
댓글 기능의 개요
게시판을 보면 하나의 게시글에 수많은 댓글이 달리는데 이러한 관계를 1:n 관계라고 한다.
댓글 입장에서 보면 여러 댓글이 하나의 게시글에 달리므로 n:1 관계라고 한다.

위의 그림을 보면 article 테이블과 comment 테이블이 id를 기준으로 관계를 맺고 있다.
두 테이블 모두 자신을 대표하는 id가 있는데 이것을 대표키 즉 PK라고 하며 PK는 중복된 값이 없어야 한다.
comment 테이블에는 연관 대상을 가리키는 article_id가 하나 더 있는데 이런 것을 외래키라고 한다.
외래키를 따라가면 해당 댓글이 어떤 게시글에 달린 것인지 알 수 있다.
게시판 작성을 위해 Article 엔티티와 ArticleRepository를 작성한 것처럼,
댓글 작성을 위한 Comment 엔티티와 CommentRepository를 만들어 준다.
이번에는 CommentRepository에다가 엔티티를 페이지 단위로 조회 및 정렬 기능이 포함된 JpaRepository를 상속받을 것이다.
댓글 엔티티 만들기
com.example.firstproject > entity에서 Comment라는 이름으로 새 댓글 엔티티 파일을 생성하고,
아래와 같이 주석과 함께 코드를 추가해 준다.
package com.example.firstproject.entity;
import jakarta.persistence.*;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.ToString;
@Entity // 해당 클래스가 엔티티임을 선언
@Getter // 각 필드 값을 조회할 수 있는 getter 메서드 자동 생성
@ToString // 모든 필드를 출력할 수 있는 toString 메서드 자동 생성
@AllArgsConstructor // 모든 필드를 매개변수로 갖는 생상자 자동 생성
@NoArgsConstructor // 매개변수가 아예 없는 기본 생성자 자동 생성
public class Comment {
@Id // 대표키 지정
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id; // pk
@ManyToOne // Comment 엔티티와 Article 엔티티를 다대다 관계로 설정
@JoinColumn(name = "article_id") // 외래키 생성
private Article article; // 부모 게시글
@Column // 해당 필드를 테이블의 속성으로 매핑
private String nickname; // 댓글 작성자
@Column // 해당 필드를 테이블의 속성으로 매핑
private String body; // 댓글 본문
}엔티티의 동작을 확인하기 위해 FirstprojectApplication.java 파일을 열고,
클래스 시작 행에 있는 실행 버튼을 클릭해 실행시킨 후 로그를 보면 아래와 같이 테이블이 생성된 것을 볼 수 있다.
테이블이 정말 만들어졌는지는 DB에 접속해 보면 아래와 같이 정상적으로 생성된 것을 볼 수 있다.
하지만 현재 테이블은 비어 있으니 기본 더미 데이터를 추가해 볼 것인데 data.sql 파일을 열어 아래와 같이 쿼리를 추가해 준다.
-- 기존 데이터
INSERT INTO article(title, content) VALUES ('가가가가', '1111');
INSERT INTO article(title, content) VALUES ('나나나나', '2222');
INSERT INTO article(title, content) VALUES ('다다다다', '3333');
-- article 테이블에 데이터 추가
INSERT INTO article(title, content) VALUES ('당신의 인생 영화는?', '댓글 작성1');
INSERT INTO article(title, content) VALUES ('당신의 소울 푸드는?', '댓글 작성2');
INSERT INTO article(title, content) VALUES ('당신의 취미는?', '댓글 작성3');
-- 4번 게시글의 댓글 추가
INSERT INTO comment(article_id, nickname, body) VALUES (4, 'Park', '굿 월 헌팅');
INSERT INTO comment(article_id, nickname, body) VALUES (4, 'Kim', '아이 엠 샘');
INSERT INTO comment(article_id, nickname, body) VALUES (4, 'Choi', '쇼생크 탈출');
-- 5번 게시글의 댓글 추가
INSERT INTO comment(article_id, nickname, body) VALUES (5, 'Park', '치킨');
INSERT INTO comment(article_id, nickname, body) VALUES (5, 'Kim', '샤브샤브');
INSERT INTO comment(article_id, nickname, body) VALUES (5, 'Choi', '초밥');
-- 6번 게시글의 댓글 추가
INSERT INTO comment(article_id, nickname, body) VALUES (6, 'Park', '유튜브 시청');
INSERT INTO comment(article_id, nickname, body) VALUES (6, 'Kim', '독서');
INSERT INTO comment(article_id, nickname, body) VALUES (6, 'Choi', '조깅');
서버를 재시작하고 h2-console 페이지에 접속해서 테이블을 조회하면 데이터가 삽입된 것을 확인할 수 있다.

이제 댓글 조회 쿼리를 연습해 볼 것인데 쿼리와 실행 결과는 아래와 같다.
-- 특정 게시글의 모든 댓글 조회
SELECT *
FROM COMMENT
WHERE article_id = 4;
-- 특정 닉네임의 모든 댓글 조회
SELECT *
FROM COMMENT
WHERE nickname = 'Park';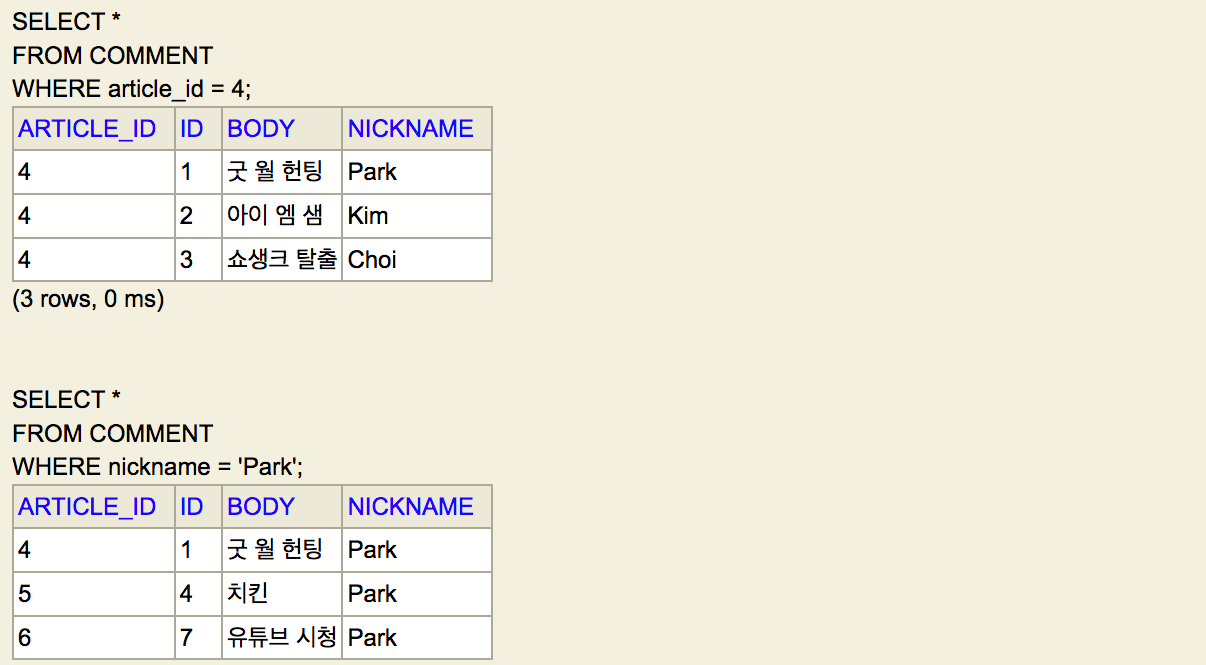
댓글 레파지토리 만들기
이제 레파지토리를 만들고 테스트 코드를 작성해 코드 검증까지 해 보도록 하겠다.
프로젝트 탐색기의 repository에서 CommentRepository 인터페이스를 만들어 JpaRepository를 상속받도록 해 준다.
package com.example.firstproject.repository;
import com.example.firstproject.entity.Comment;
import org.springframework.data.jpa.repository.JpaRepository;
public interface CommentRepository extends JpaRepository<Comment, Long> {
}다음으로 앞서 연습한 두 쿼리를 메서드로 아래와 같이 작성해 준다.
특정 게시글의 모든 댓글을 조회하기 위해 쿼리를 메서드로 작성하는 네이티브 쿼리 메서드로 SQL 쿼리를 작성해 준다.
@Query 어노테이션을 활용하여 작성하거나 orm.xml 파일을 이용하는 방법이 존재한다.
// 특정 게시글의 모든 댓글 조회
@Query(value = "SELECT * FROM comment WHERE article_id = :articleId", nativeQuery = true)
List<Comment> findByArticleId(Long articleId);
// 특정 닉네임의 모든 댓글 조회
List<Comment> findByNickname(String nickname);findByNickname() 메서드에서 수행할 쿼리를 이번에는 네이티브 쿼리 XML 기본경로인 META-INF에다가,
orm.xml 이라는 이름으로 파일을 생성하고 아래와 같이 작성해 준다.
<?xml version="1.0" encoding="utf-8" ?>
<entity-mappings xmlns="https://jakarta.ee/xml/ns/persistence/orm"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://jakarta.ee/xml/ns/persistence/orm
https://jakarta.ee/xml/ns/persistence/orm/orm_3_0.xsd"
version="3.0">
<named-native-query
name="Comment.findByNickname"
result-class="com.example.firstproject.entity.Comment">
<query>
<![CDATA[
SELECT * FROM comment WHERE nickname = :nickname
]]>
</query>
</named-native-query>
</entity-mappings>서버를 재시작하여 아래와 같이 문제없이 동작하는지 확인을 한 번 해 준다.

이어서 findByArticleId() 메서드와 findByNickname() 메서드가 문제없이 동작하는지 테스트 코드를 작성해 확인해 볼 것이다.
findByArticleId() 메서드 위로 마우스를 올리고 Generate -> Test 선택해 파일을 아래와 같이 생성해 준다.
package com.example.firstproject.repository;
import org.junit.jupiter.api.Test;
class CommentRepositoryTest {
@Test
void findByArticleId() {
}
@Test
void findByNickname() {
}
}그다음 레파지토리를 테스트하므로 @DataJpaTest 어노테이션을 붙여주고,
레파지토리를 테스트하기 위해 commentRepository 객체를 선언하고 @Autowired를 붙이는 것도 잊지 말고 해 준다.
...
@DataJpaTest // 해당 클래스를 JPA와 연동해 테스팅
class CommentRepositoryTest {
@Autowired
CommentRepository commentRepository; // 객체 주입
...
...
}테스트의 메서드 명을 한글로 수정하지 않고 @DisplayName 어노테이션으로 테스트 이름을 붙여준다.
그다음은 테스트 케이스를 여러 개 작성할 것이니 테스트마다 중괄호로 묶고 주석과 함께 코드를 작성해 준다.
먼저 4번 게시글의 모든 댓글을 조회하는 테스트를 해 볼 것인데 유의할 점은,
3번째 단계인 예상 데이터 작성에서 부모 게시글 객체를 먼저 생성하고 댓글 객체들을 생성해 주고 합쳐야 한다.
/* Case 1: 4번 게시글의 모든 댓글 조회 */
{
// 1. 입력 데이터 준비
Long articleId = 4L;
// 2. 실제 데이터
List<Comment> comments = commentRepository.findByArticleId(articleId);
// 3. 에상 데이터
Article article = new Article(4L, "당신의 인생 영화는?", "댓글 고"); // 부모 게시글 생성
Comment a = new Comment(1L, article, "Park", "굿 윌 헌팅"); // 댓글 객체 생성
Comment b = new Comment(2L, article, "Kim", "아이 엠 샘"); // 댓글 객체 생성
Comment c = new Comment(3L, article, "Choi", "쇼생크 탈출"); // 댓글 객체 생성
List<Comment> expected = Arrays.asList(a, b, c); // 댓글 객체 합치기
// 4. 비교 및 검증
assertEquals(expected.toString(), comments.toString());
}두 번째 케이스는 댓글이 하나도 없는 1번 게시글의 댓글을 조회하려고 할 때를 테스트해 볼 것인데 코드는 아래와 같다.
/* Case 2: 1번 게시글의 모든 댓글 조회 */
{
// 1. 입력 데이터 준비
Long articleId = 1L;
// 2. 실제 데이터
List<Comment> comments = commentRepository.findByArticleId(articleId);
// 3. 예상 데이터
Article article = new Article(1L, "가가가가", "1111");
List<Comment> expected = Arrays.asList();
// 4. 비교 및 검증
assertEquals(expected.toString(), comments.toString(), "1번 글은 댓글이 없음");
}이번에는 특정 닉네임의 모든 댓글을 조회할 것인데 위와 유사하게 코드를 작성해 주면 된다.
@Test
@DisplayName("특정 닉네임의 모든 댓글 조회")
void findByNickname() {
/* Case 1: "Park"의 모든 댓글 조회 */
{
// 1. 입력 데이터 준비
String nickname = "Park";
// 2. 실제 데이터
List<Comment> comments = commentRepository.findByNickname(nickname);
// 3. 예상 데이터
Comment a = new Comment(1L, new Article(4L, "당신의 인생 영화는?", "댓글 고"), nickname, "굿 윌 헌팅");
Comment b = new Comment(4L, new Article(5L, "당신의 소울 푸드는?", "댓글 고고"), nickname, "치킨");
Comment c = new Comment(7L, new Article(6L, "당신의 취미는?", "댓글 고고고"), nickname, "유튜브 시청");
List<Comment> expected = Arrays.asList(a, b, c);
// 4. 비교 및 검증
assertEquals(expected.toString(), comments.toString(), "Park의 모든 댓글을 출력!");
}
}실행한 결과 아래와 같이 테스트 코드를 통과한 것을 볼 수 있다.

테스트가 실패하는 경우를 확인해 보기 예상 데이터 a의 1L을 임의로 2L로 바꾸고 재실행하면 아래와 같이,
expected와 actual이 일치하지 않아 실패한 것을 확인할 수 있다.

'Backend' 카테고리의 다른 글
| 코딩자율학습단 스프링부트_16장 (0) | 2024.08.24 |
|---|---|
| 코딩자율학습단 스프링부트_15장 (0) | 2024.08.24 |
| 코딩자율학습단 스프링부트_13장 (0) | 2024.08.20 |
| 코딩자율학습단 스프링부트_12장 (0) | 2024.08.19 |
| 코딩자율학습단 스프링부트_11장 (0) | 2024.08.17 |